Overview
KleverAI lets operations teams detect failure risks before they materialise — guiding users through a structured ML workflow (data preparation → analysis → prediction → deployment) designed to be run by business analysts and operations managers, not data scientists. The central challenge: make a technically complex, high-stakes workflow feel manageable and trustworthy to someone who has never trained a model.
The problem
Most organisations had the data to predict operational failures — they just couldn't act on it. Existing ML tools required Python expertise to run, or delivered black-box predictions with no explanation of reasoning. Non-specialist teams were stuck: one option was too technical, the other too opaque to trust.
The outcome was the same in both cases. Data sat unused. Warnings arrived too late or not at all. Preventable failures recurred — not for lack of information, but because the interface between the data and the decision-maker was broken.
Design approach
The foundational decision was to make the workflow strictly linear and non-skippable. You cannot jump from data preparation to deployment. You cannot run a prediction on uncleaned data. This is unusual for enterprise software, which typically allows free navigation. But the ML workflow has hard logical dependencies — enforcing the sequence in the UI wasn't a constraint, it was the core design principle.
Each stage has a defined entry state, a progress indicator, and a locked exit condition. Users always know where they are and exactly what's required to advance.
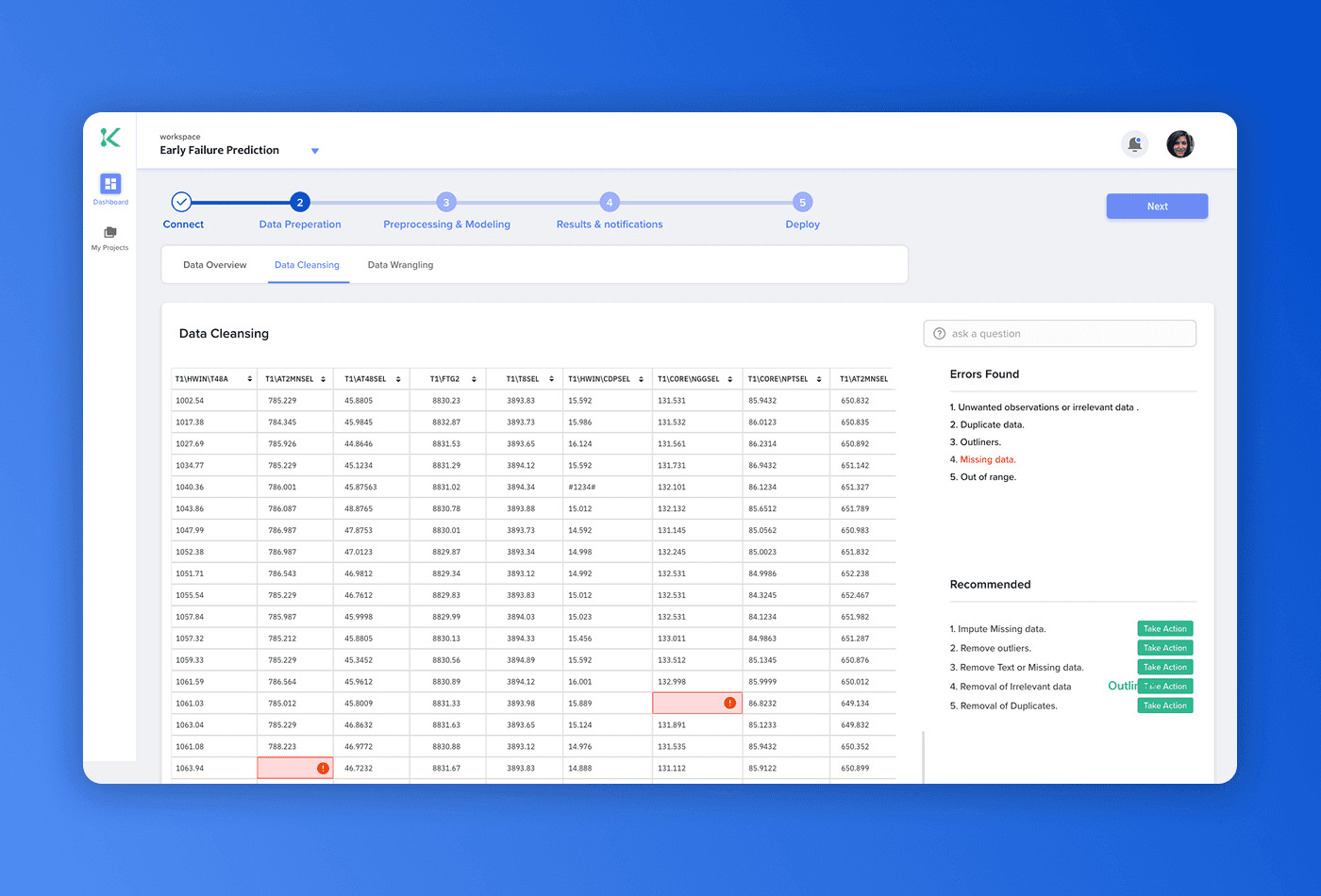
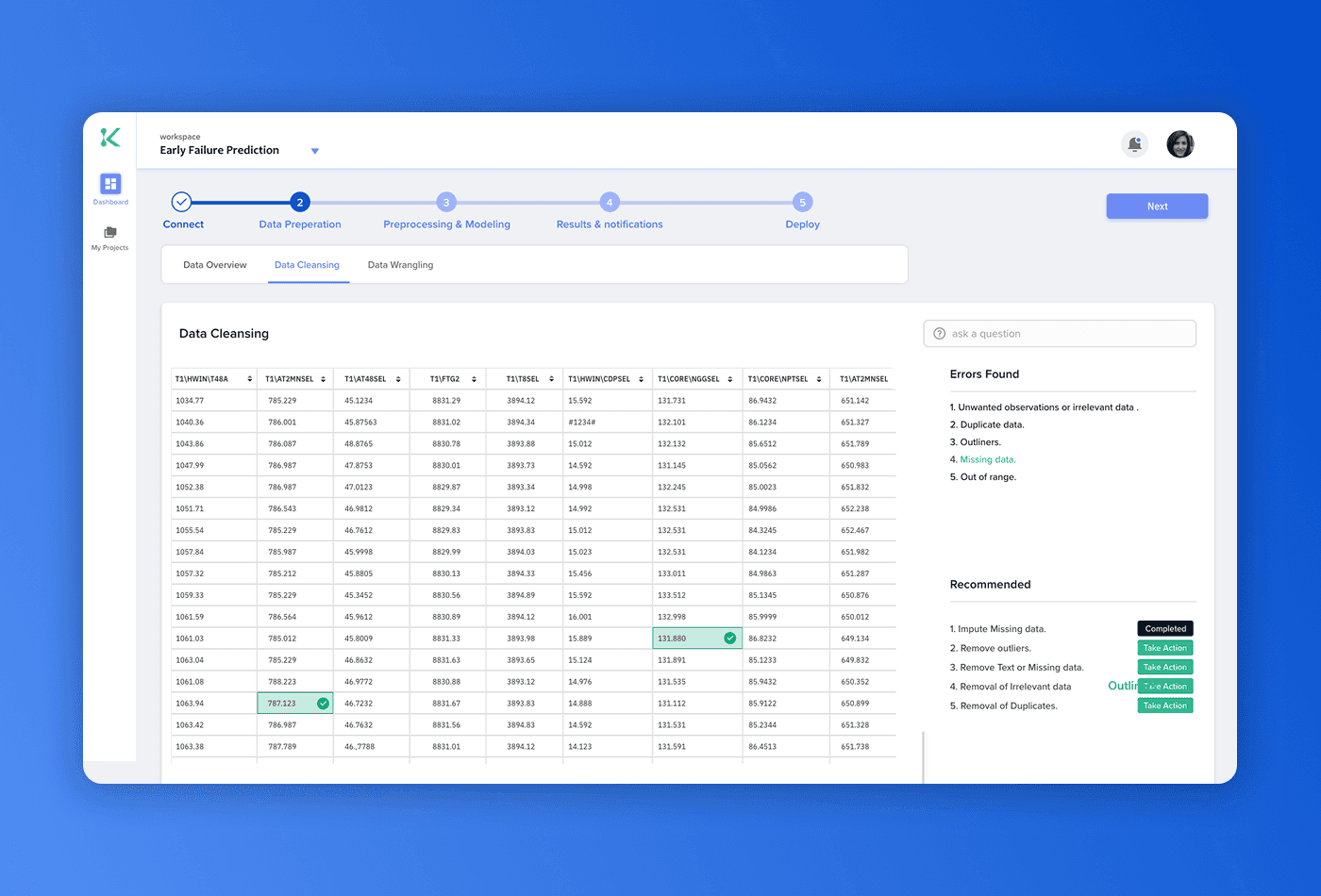
The data correction step was the hardest screen to design. The obvious approach — a list of errors — forces the user to mentally map each issue back to its location in the dataset. Instead, we surfaced errors inside the table, precisely where they occur. Missing values show as flagged empty cells; outliers carry visual markers in-situ. The "Take Action" panel anchors to the affected region, pairing the problem with its recommended fix in the same visual space before the user confirms anything.
Key decisions
Enforced linearity as a feature, not a limitation. Early stakeholder feedback pushed for free navigation — "power users will want to jump around." We pushed back. Allowing skipped steps would produce invalid models and erode trust in the platform's outputs. Instead of opening up navigation, we invested in making each step faster and clearer so the linear path felt efficient, not restrictive.
Confidence scores changed how users acted. Adding a visible confidence percentage alongside each prediction transformed the platform from "interesting tool" to "operational infrastructure." High-confidence predictions got immediate escalation. Low-confidence ones went to a specialist. One number added to the output reshaped the entire workflow around it.
Deployment as a deliberate act. The final step before deployment isn't a button — it's a review screen: what model will run, on what schedule, alerting which teams, with a changelog against the previous deployment. This made deployment feel considered rather than accidental, and built genuine trust with operations teams who'd been burned by runaway automation before.